生产环境的 "达摩克利斯之剑"
想象一下这个场景:凌晨三点,你被急促的电话铃声惊醒,运维团队告诉你,线上订单系统响应时间从 50ms 飙升到了 5000ms,大量用户投诉无法完成支付。排查后发现,正是昨天下午你主导上线的 "给订单表新增一个字段" 的操作导致的。
这不是危言耸听,而是真实发生在 2023 年某电商平台的生产事故。根据 MySQL官方文档(https://dev.mysql.com/doc/refman/8.0/en/alter-table.html),当对大型表执行 ALTER TABLE 操作时,可能会导致表锁定、性能下降甚至服务中断。对于千万级别的订单表来说,这种操作的风险被放大了无数倍。
我经历过数次千万级表的结构变更,踩过的坑能写一本小册子。本文将从底层原理到实战操作,全方位解析千万级订单表新增字段的正确姿势,让你从 "不敢动" 变成 "大胆改",更重要的是 "安全改"。
一、千万级订单表的特殊性
在讨论如何新增字段之前,我们首先需要理解千万级订单表的特殊性。这些特性决定了我们不能用对待小表的方式来处理它们。
1.1 数据量与存储特性
千万级订单表通常意味着:
记录数在 1000 万到数亿之间
表空间可能达到 GB 甚至 TB 级别
索引数量多,索引文件体积庞大
根据 MySQL 官方性能测试报告(https://dev.mysql.com/doc/performance-schema/8.0/en/),当表记录数超过 1000 万时,常规的 ALTER TABLE 操作时间会呈指数级增长。
1.2 高并发访问特性
订单表作为核心业务表,通常具有:
读写频率高,尤其是在促销活动期间
事务性要求高,涉及支付、库存等关键操作
与多个上下游系统存在依赖关系
阿里巴巴《Java 开发手册(嵩山版)》明确指出:"对于核心业务表的结构变更,必须进行充分的风险评估和影响范围分析"。
1.3 性能敏感特性
订单表的性能直接影响:
用户体验(支付流程是否顺畅)
系统稳定性(是否会引发连锁反应)
业务收入(每秒钟的延迟都可能造成直接损失)
Google 在 SRE 书籍中提到:"核心交易系统的可用性目标应该达到 99.99% 以上,意味着每年允许的不可用时间不超过 52.56 分钟"。
二、新增字段的底层原理
要理解为什么千万级表新增字段风险大,我们需要先了解 MySQL 在执行 ALTER TABLE 操作时的底层原理。
2.1 MySQL 的表结构变更机制
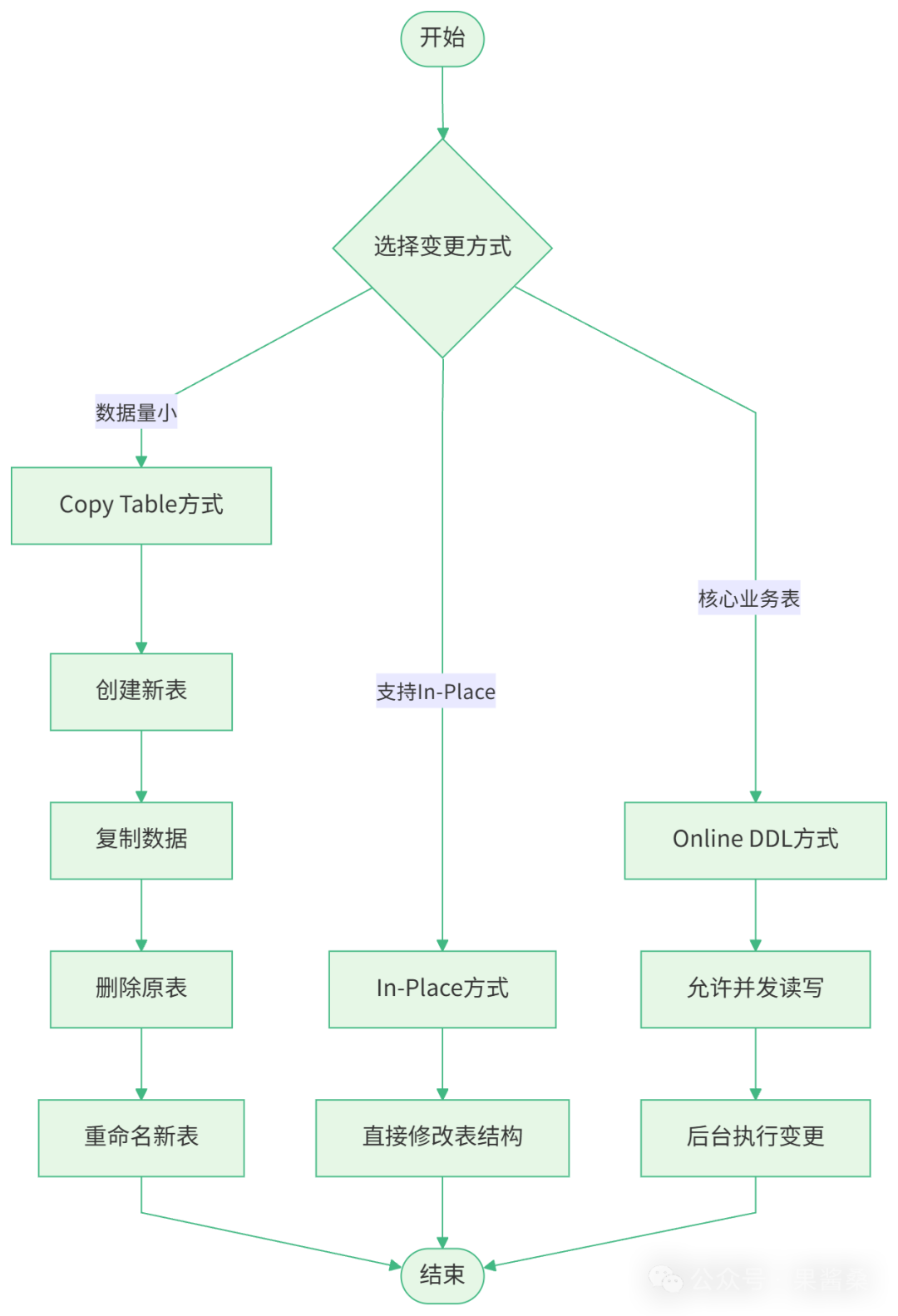
MySQL 执行 ALTER TABLE 操作主要有三种方式(参考 MySQL 官方文档):
Copy Table 方式:创建一个新表,将原表数据逐条复制到新表,然后删除原表,重命名新表。这是最原始的方式,会产生大量 IO 操作,并且在复制期间表会被锁定。
In-Place 方式:在原表上直接修改表结构,不需要创建临时表。这种方式速度快,锁表时间短,但并不是所有 ALTER 操作都支持。
Online DDL 方式:允许在执行 ALTER 操作的同时,继续进行读写操作。这是 MySQL 5.6 及以上版本引入的特性,极大地提高了大表结构变更的安全性。
流程图如下:
2.2 新增字段对性能的影响
新增字段看似简单,但在千万级表上可能引发一系列性能问题:
锁表风险:如果使用 Copy Table 方式,会导致长时间表锁定,无法进行读写操作。
IO 风暴:大量数据复制会占用大量 IO 资源,影响其他业务的正常运行。
事务日志暴涨:ALTER 操作会产生大量事务日志,可能导致磁盘空间不足。
索引重建:某些情况下,新增字段可能导致索引重建,这对大表来说是极其耗时的操作。
Percona 的性能测试显示,在 1000 万行的 InnoDB 表上新增一个字段,使用 Copy Table 方式可能需要数小时,而使用 Online DDL 方式可能只需要几分钟(https://www.percona.com/blog/2013/07/19/online-ddl-in-mysql-5-6-performance/)。
三、新增字段的前期准备
在动手操作之前,充分的准备工作是必不可少的。这部分工作做得越充分,后续操作的风险就越低。
3.1 业务影响评估
首先需要明确新增字段的必要性和紧迫性:
是否必须新增:能否通过扩展表或冗余字段的方式避免修改主表?
影响范围:哪些系统、哪些接口会受到影响?
实施窗口:选择业务低峰期进行操作,如凌晨 2 点到 4 点。
回滚方案:如果出现问题,如何快速回滚?
示例:某电商平台订单表新增字段影响评估表
3.2 技术方案设计
根据业务需求和表特性,设计详细的技术方案:
字段定义:字段名、类型、长度、默认值等。遵循阿里巴巴《Java 开发手册》中的命名规范,如字段名使用 lowerCamelCase 风格。
索引考虑:新增字段是否需要建立索引?如果需要,是在新增字段时同时创建,还是分阶段创建?
默认值处理:如果设置默认值,需要考虑对已有数据的影响。
变更方式:选择合适的 ALTER 方式,优先考虑 Online DDL。
示例:订单表新增字段技术方案
ALTER TABLE `order` ADD COLUMN `promotion_type` tinyint(1) NOT NULL DEFAULT 0 COMMENT '促销类型:0-无促销,1-满减,2-折扣,3-优惠券' AFTER `pay_amount`;
3.3 环境准备
测试环境验证:在与生产环境配置相同的测试环境进行多次演练,记录操作时间和资源消耗。
生产环境备份:执行 ALTER 操作前,必须对表进行全量备份。
-- 备份订单表mysqldump -u root -p --databases order_db --tables `order` > order_backup_20231001.sql
资源监控准备:准备好监控脚本或工具,实时监控 CPU、内存、IO、连接数等指标。
示例:MySQL 性能监控脚本(使用 Percona Monitoring and Management)
while true; do date mysql -u root -p -e "show global status like 'Threads_connected'" sleep 5done > mysql_connections_monitor.log 2>&1
四、新增字段的四种方案及实战
根据不同的业务场景和风险承受能力,我们可以选择不同的方案来新增字段。下面详细介绍四种常用方案及其适用场景。
4.1 方案一:直接 ALTER TABLE(简单但风险高)
这是最直接的方式,适用于数据量相对较小(如 1000 万以下)且业务能接受短时间锁表的场景。
4.1.1 操作步骤
编写 ALTER SQL 语句
ALTER TABLE `order` ADD COLUMN `promotion_type` tinyint(1) NOT NULL DEFAULT 0 COMMENT '促销类型:0-无促销,1-满减,2-折扣,3-优惠券' AFTER `pay_amount`;
执行 SQL 语句
在生产环境执行前,必须再次确认:
验证结果
-- 检查字段是否添加成功
DESCRIBE`order`;
-- 检查默认值是否正确
SELECT COUNT(*) FROM `order` WHERE `promotion_type` != 0;
4.1.2 Java 代码适配
实体类新增字段:
import lombok.Data;import lombok.extern.slf4j.Slf4j;import com.baomidou.mybatisplus.annotation.IdType;import com.baomidou.mybatisplus.annotation.TableId;import com.baomidou.mybatisplus.annotation.TableField;import com.baomidou.mybatisplus.annotation.TableName;import io.swagger.v3.oas.annotations.media.Schema;
* 订单实体类 * * @author 果酱 */@Data@Slf4j@TableName("`order`")@Schema(description = "订单信息")public class Order {
@TableId(type = IdType.AUTO) @Schema(description = "订单ID") private Long id;
@Schema(description = "用户ID") private Long userId;
@Schema(description = "订单金额") private BigDecimal orderAmount;
@Schema(description = "支付金额") private BigDecimal payAmount;
* 新增促销类型字段 * 0-无促销,1-满减,2-折扣,3-优惠券 */ @TableField("promotion_type") @Schema(description = "促销类型:0-无促销,1-满减,2-折扣,3-优惠券") private Integer promotionType;
}
Mapper 接口无需修改,MyBatis-Plus 会自动映射新增字段。
Service 层处理:
import org.springframework.stereotype.Service;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;import org.apache.commons.lang3.StringUtils;import java.util.Objects;import lombok.extern.slf4j.Slf4j;import io.swagger.v3.oas.annotations.Operation;import io.swagger.v3.oas.annotations.tags.Tag;
* 订单服务实现类 * * @author 果酱 */@Service@Slf4j@Tag(name = "订单服务", description = "订单相关操作")public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements OrderService {
@Override @Operation(summary = "创建订单", description = "新增订单记录") public Long createOrder(OrderCreateDTO orderCreateDTO) { Objects.requireNonNull(orderCreateDTO, "订单创建参数不能为空"); log.info("开始创建订单,用户ID:{}", orderCreateDTO.getUserId());
Order order = new Order(); order.setUserId(orderCreateDTO.getUserId()); order.setOrderAmount(orderCreateDTO.getOrderAmount()); order.setPayAmount(orderCreateDTO.getPayAmount());
order.setPromotionType(Objects.requireNonNullElse(orderCreateDTO.getPromotionType(), 0));
save(order); log.info("订单创建成功,订单ID:{}", order.getId()); return order.getId(); }
}
4.1.3 优缺点分析
优点:
操作简单,只需一条 SQL 语句
无需修改应用架构
开发成本低
缺点:
可能导致长时间锁表
对数据库性能影响大
不适合超大规模表
适用场景:1000 万行以下的表,非核心业务表,可接受短时间服务降级。
4.2 方案二:Online DDL(平衡风险和复杂度)
MySQL 5.6 及以上版本支持 Online DDL,允许在执行 ALTER 操作时,表仍然可以被读取和写入。这是处理千万级订单表的推荐方案之一。
4.2.1 操作步骤
编写带 ALGORITHM 和 LOCK 选项的 ALTER 语句
ALTER TABLE `order` ADD COLUMN `promotion_type` tinyint(1) NOT NULL DEFAULT 0 COMMENT '促销类型:0-无促销,1-满减,2-折扣,3-优惠券' AFTER `pay_amount`ALGORITHM=INPLACE LOCK=NONE;
参数说明:
- ALGORITHM=INPLACE:表示使用 In-Place 方式,不创建临时表
- LOCK=NONE:表示允许在 ALTER 过程中进行读写操作
执行过程中,可以通过以下语句监控进度:
SELECT * FROM information_schema.processlist WHERE state LIKE 'alter%';
4.2.2 注意事项
不是所有 ALTER 操作都支持 ALGORITHM=INPLACE 和 LOCK=NONE,具体可参考 MySQL 官方文档(https://dev.mysql.com/doc/refman/8.0/en/innodb-online-ddl-operations.html)
Online DDL 虽然允许并发操作,但仍然会对性能产生影响,尤其是在操作期间
对于非常大的表,即使使用 Online DDL,也可能需要较长时间
4.2.3 优缺点分析
优点:
锁表时间极短,几乎不影响业务
相比方案一,安全性高很多
操作相对简单
缺点:
仍然会消耗大量数据库资源
不支持所有类型的 ALTER 操作
可能导致主从延迟增大
适用场景:千万级订单表,核心业务表,需要在不中断服务的情况下进行变更。
4.3 方案三:影子表迁移(复杂但最安全)
影子表迁移是最安全但也最复杂的方案,适用于对可用性要求极高的核心订单表。
4.3.1 操作原理
创建一个与原表结构相同的影子表
向影子表添加新字段
同步原表数据到影子表
切换读写流量到影子表
删除原表,将影子表重命名为原表名
架构图如下:
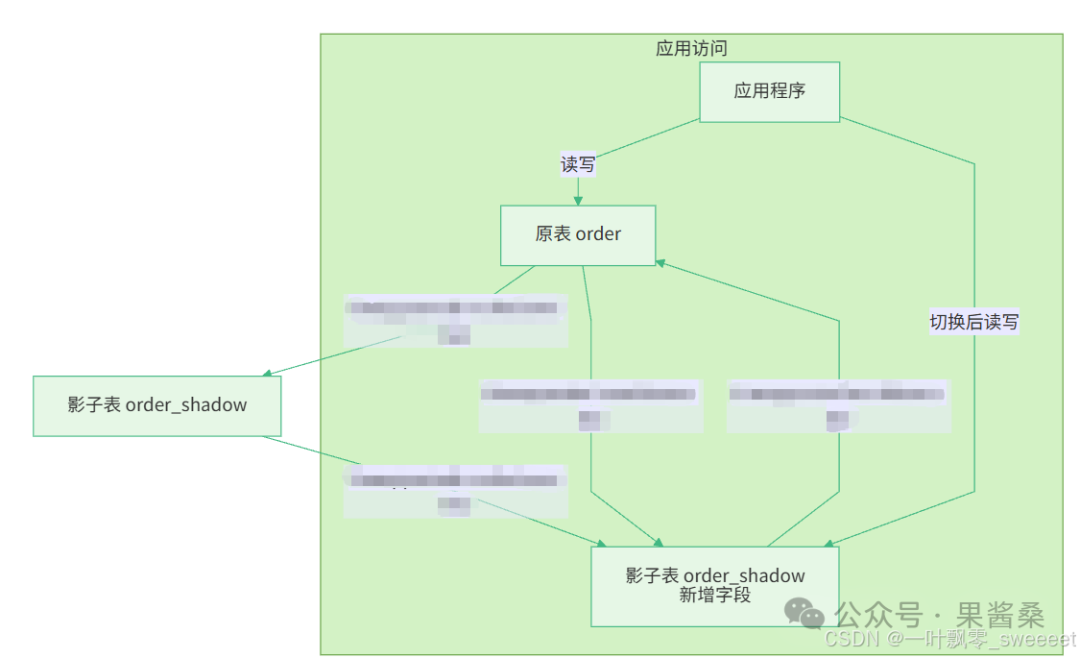
4.3.2 操作步骤
创建影子表
CREATE TABLE `order_shadow` LIKE `order`;
ALTER TABLE `order_shadow` ADD COLUMN `promotion_type` tinyint(1) NOT NULL DEFAULT 0 COMMENT '促销类型:0-无促销,1-满减,2-折扣,3-优惠券' AFTER `pay_amount`;
可以使用 INSERT INTO ... SELECT 语句批量同步:
INSERT INTO `order_shadow` SELECT *, 0 FROM `order` WHERE id > (SELECT MAX(id) FROM `order_shadow`) LIMIT 100000;
为避免一次性同步大量数据对数据库造成压力,建议分批次同步,并在业务低峰期执行。
使用触发器同步新增和修改的数据:
DELIMITER //CREATE TRIGGER `order_after_insert` AFTER INSERT ON `order`FOR EACH ROWBEGIN INSERT INTO `order_shadow` VALUES (NEW.*, 0);END //DELIMITER ;
DELIMITER //CREATE TRIGGER `order_after_update` AFTER UPDATE ON `order`FOR EACH ROWBEGIN UPDATE `order_shadow` SET user_id = NEW.user_id, order_amount = NEW.order_amount, pay_amount = NEW.pay_amount, promotion_type = 0 WHERE id = NEW.id;END //DELIMITER ;
SELECT COUNT(*) FROM `order`;SELECT COUNT(*) FROM `order_shadow`;
SELECT * FROM `order` WHERE id IN (SELECT id FROM `order` ORDER BY RAND() LIMIT 100);SELECT * FROM `order_shadow` WHERE id IN (SELECT id FROM `order` ORDER BY RAND() LIMIT 100);
在应用程序中添加路由逻辑,将读写操作切换到影子表。
示例:使用 MyBatis-Plus 的动态表名功能
import com.baomidou.mybatisplus.extension.plugins.handler.TableNameHandler;import org.springframework.stereotype.Component;
* 订单表动态表名处理器 * * @author 果酱 */@Componentpublic class OrderTableNameHandler implements TableNameHandler {
* 是否切换到影子表的开关 */ private static boolean useShadowTable = false;
@Override public String dynamicTableName(String sql, String tableName) { if ("order".equals(tableName) && useShadowTable) { return "order_shadow"; } return tableName; }
* 设置是否使用影子表 */ public static void setUseShadowTable(boolean useShadow) { useShadowTable = useShadow; }}
配置 MyBatis-Plus 插件:
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;import com.baomidou.mybatisplus.extension.plugins.handler.TenantLineHandler;import com.baomidou.mybatisplus.extension.plugins.inner.DynamicTableNameInnerInterceptor;import com.baomidou.mybatisplus.extension.plugins.inner.TenantLineInnerInterceptor;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import java.util.HashMap;import java.util.Map;
* MyBatis-Plus配置 * * @author 果酱 */@Configurationpublic class MyBatisPlusConfig {
@Bean public MybatisPlusInterceptor mybatisPlusInterceptor(OrderTableNameHandler orderTableNameHandler) { MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
DynamicTableNameInnerInterceptor dynamicTableNameInnerInterceptor = new DynamicTableNameInnerInterceptor(); Map<String, TableNameHandler> tableNameHandlerMap = new HashMap<>(); tableNameHandlerMap.put("order", orderTableNameHandler); dynamicTableNameInnerInterceptor.setTableNameHandlerMap(tableNameHandlerMap);
interceptor.addInnerInterceptor(dynamicTableNameInnerInterceptor); return interceptor; }}
切换表的服务类:
import org.springframework.stereotype.Service;import lombok.extern.slf4j.Slf4j;import io.swagger.v3.oas.annotations.Operation;import io.swagger.v3.oas.annotations.tags.Tag;
* 表切换服务 * * @author 果酱 */@Service@Slf4j@Tag(name = "表切换服务", description = "订单表与影子表切换")public class TableSwitchService {
@Operation(summary = "切换到影子表", description = "将读写流量切换到影子表") public void switchToShadowTable() { log.info("开始切换到影子表"); OrderTableNameHandler.setUseShadowTable(true); log.info("已切换到影子表"); }
@Operation(summary = "切换回原表", description = "将读写流量切换回原表") public void switchToOriginalTable() { log.info("开始切换回原表"); OrderTableNameHandler.setUseShadowTable(false); log.info("已切换回原表"); }}
在确认数据一致后,执行切换操作:
tableSwitchService.switchToShadowTable();
观察应用日志,确认所有操作都已指向影子表,并且业务正常运行。
DROP TABLE `order`;
ALTER TABLE `order_shadow` RENAME TO `order`;
DROP TRIGGER `order_after_insert`;DROP TRIGGER `order_after_update`;
tableSwitchService.switchToOriginalTable();
4.3.3 优缺点分析
优点:
几乎不影响线上业务,安全性最高
可以在切换前充分验证新表结构
出现问题时可以快速回滚
缺点:
操作复杂,步骤多
需要修改应用代码
耗时较长,可能需要数天时间
适用场景:亿级订单表,核心交易系统,对可用性要求极高的场景。
4.4 方案四:分表分库场景下的新增字段
在分布式系统中,订单表通常会进行分表分库处理。这种情况下新增字段需要特殊处理。
4.4.1 操作原理
先在所有从表上新增字段
逐步切换分表路由,验证每个分表的可用性
最后在主表上新增字段
4.4.2 操作步骤
确定分表规则和所有分表名称
假设订单表按用户 ID 哈希分表,共 16 个分表:order_0 到 order_15。
编写批量新增字段的脚本
#!/bin/bash
USER="root"PASSWORD="your_password"DATABASE="order_db"
TABLE_COUNT=16
for ((i=0; i<TABLE_COUNT; i++)); do TABLE_NAME="order_$i" echo "开始处理表:$TABLE_NAME"
mysql -u $USER -p$PASSWORD $DATABASE -e " ALTER TABLE $TABLE_NAME ADD COLUMN \`promotion_type\` tinyint(1) NOT NULL DEFAULT 0 COMMENT '促销类型:0-无促销,1-满减,2-折扣,3-优惠券' AFTER \`pay_amount\` ALGORITHM=INPLACE LOCK=NONE; "
if [ $? -eq 0 ]; then echo "表 $TABLE_NAME 处理成功" else echo "表 $TABLE_NAME 处理失败" exit 1 fidone
echo "所有分表处理完成"
执行脚本,为所有分表新增字段
验证每个分表的结构
DESCRIBE order_0;DESCRIBE order_1;
与单表情况类似,需要在实体类中新增字段。分表路由逻辑无需修改,因为分表规则没有变化。
4.4.3 注意事项
分表分库场景下,建议逐个分表进行操作,而不是同时操作所有分表,以避免数据库负载过高。
对于非常多的分表(如 100+),可以考虑分批处理,每批处理几个分表。
操作过程中要密切监控数据库性能和主从同步状态。
4.4.4 优缺点分析
优点:
适合分布式系统场景
可以分批处理,降低风险
不影响整体分表策略
缺点:
操作繁琐,尤其是分表数量多时
需要协调多个数据库节点
验证工作复杂
适用场景:分表分库的订单系统,分布式架构下的千万级甚至亿级订单表。
五、新增字段后的验证与优化
新增字段不是结束,还需要进行充分的验证和必要的优化。
5.1 功能验证
基础功能验证
import org.junit.jupiter.api.Test;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.test.context.SpringBootTest;import static org.junit.jupiter.api.Assertions.*;
* 订单表新增字段功能测试 * * @author 果酱 */@SpringBootTestpublic class OrderFieldAdditionTest {
@Autowired private OrderService orderService;
@Autowired private OrderMapper orderMapper;
@Test public void testPromotionTypeField() { OrderCreateDTO createDTO = new OrderCreateDTO(); createDTO.setUserId(10001L); createDTO.setOrderAmount(new BigDecimal("99.99")); createDTO.setPayAmount(new BigDecimal("99.99")); createDTO.setPromotionType(1);
Long orderId = orderService.createOrder(createDTO); assertNotNull(orderId, "订单创建失败");
Order order = orderMapper.selectById(orderId); assertNotNull(order, "订单查询失败"); assertEquals(1, order.getPromotionType().intValue(), "促销类型字段值不正确");
OrderCreateDTO defaultDTO = new OrderCreateDTO(); defaultDTO.setUserId(10001L); defaultDTO.setOrderAmount(new BigDecimal("199.99")); defaultDTO.setPayAmount(new BigDecimal("199.99"));
Long defaultOrderId = orderService.createOrder(defaultDTO); Order defaultOrder = orderMapper.selectById(defaultOrderId); assertEquals(0, defaultOrder.getPromotionType().intValue(), "促销类型默认值不正确"); }}
关联功能验证:验证与新增字段相关的业务功能是否正常。
边界条件验证:如字段的最大值、最小值、特殊值等。
5.2 性能优化
索引优化
ALTER TABLE `order` ADD INDEX idx_promotion_type (`promotion_type`) ALGORITHM=INPLACE LOCK=NONE;
注意:添加索引会影响写入性能,需要评估后再决定。
- SQL 优化
检查涉及新增字段的 SQL 语句,确保使用了合适的索引。
EXPLAIN SELECT * FROM `order` WHERE promotion_type = 1;
- 缓存优化
如果新增字段频繁被访问,考虑在缓存中也添加该字段。
示例:Redis 缓存更新
* 订单缓存服务 * * @author 果酱 */@Service@Slf4jpublic class OrderCacheService {
@Autowired private StringRedisTemplate redisTemplate;
@Autowired private OrderMapper orderMapper;
private static final String ORDER_KEY_PREFIX = "order:info:"; private static final Duration EXPIRATION = Duration.ofHours(24);
* 获取订单信息(带缓存) */ public Order getOrderById(Long orderId) { Objects.requireNonNull(orderId, "订单ID不能为空");
String key = ORDER_KEY_PREFIX + orderId; String json = redisTemplate.opsForValue().get(key);
if (StringUtils.hasText(json)) { log.info("从缓存获取订单信息,订单ID:{}", orderId); return JSON.parseObject(json, Order.class); }
log.info("从数据库获取订单信息,订单ID:{}", orderId); Order order = orderMapper.selectById(orderId); if (Objects.nonNull(order)) { redisTemplate.opsForValue().set(key, JSON.toJSONString(order), EXPIRATION); }
return order; }
* 更新订单缓存,包含新增字段 */ public void updateOrderCache(Order order) { Objects.requireNonNull(order, "订单对象不能为空"); Objects.requireNonNull(order.getId(), "订单ID不能为空");
String key = ORDER_KEY_PREFIX + order.getId(); redisTemplate.opsForValue().set(key, JSON.toJSONString(order), EXPIRATION); log.info("更新订单缓存,订单ID:{}", order.getId()); }}
5.3 监控与告警
添加监控指标:监控涉及新增字段的查询性能。
设置告警阈值:当性能下降到一定程度时及时告警。
示例:使用 Prometheus 监控 MySQL 性能
scrape_configs: - job_name: 'mysql' static_configs: - targets: ['mysql-exporter:9104'] metrics_path: '/metrics' scrape_interval: 10s
六、常见问题与解决方案
6.1 ALTER 操作导致表锁死
问题现象:执行 ALTER TABLE 后,表长时间处于锁定状态,无法进行读写操作。
解决方案:
- 查看当前数据库进程,找到并终止长时间运行的 ALTER 操作:
SHOW PROCESSLIST;
KILL [进程ID];
- 使用 pt-online-schema-change 工具替代原生 ALTER TABLE:
# 使用pt-online-schema-change新增字段pt-online-schema-change D=order_db,t=order \
pt-online-schema-change 是 Percona Toolkit 中的工具,通过创建影子表和触发器来实现无锁表结构变更,比 MySQL 原生的 Online DDL 兼容性更好(参考:https://www.percona.com/doc/percona-toolkit/LATEST/pt-online-schema-change.html)。
6.2 新增字段后查询性能下降
问题现象:新增字段后,某些查询的响应时间明显增加。
解决方案:
- 分析查询执行计划,检查是否因为新增字段导致索引失效:
ALTER TABLE `order` DROP INDEX idx_promotion_type,ADD INDEX idx_promotion_type (`promotion_type`)ALGORITHM=INPLACE LOCK=NONE;
6.3 主从同步延迟增大
问题现象:执行 ALTER 操作后,主从同步延迟明显增大。
解决方案:
暂停从库的备份和其他非必要操作,让从库专注于同步。
调整从库的同步参数:
SET GLOBAL slave_net_timeout = 3600;SET GLOBAL sql_slave_skip_counter = 1;
七、总结与最佳实践
7.1 核心结论
千万级订单表新增字段不是简单的 ALTER TABLE 操作,需要充分的准备和评估。
没有放之四海而皆准的方案,需要根据数据量、业务特性和可用性要求选择合适的方案。
安全性和业务连续性应该放在首位,其次才是操作复杂度和效率。
操作前后的验证工作同样重要,不能轻视。
7.2 最佳实践
小步快跑:每次只做必要的变更,避免一次进行多个字段的修改。
先测试后生产:在与生产环境一致的测试环境充分验证后,再在生产环境执行。
选择合适的时间窗口:尽量在业务低峰期进行操作,如凌晨 2 点到 4 点。
准备回滚方案:凡事预则立,不预则废,必须准备好回滚方案。
监控到底:从准备阶段到操作完成后的一段时间,都需要密切监控系统状态。
文档化:详细记录操作过程和结果,为后续类似操作提供参考。
7.3 未来趋势
随着云原生数据库的发展,如阿里云的 PolarDB、腾讯云的 TDSQL 等,它们提供了更强大的在线 DDL 能力和更低的操作风险。这些数据库通常采用分布式架构和新的存储引擎,可以实现真正的零锁表结构变更。
此外,数据库自动化运维工具的发展也使得大表结构变更越来越简单。未来,可能只需要通过简单的 API 调用,就能安全高效地完成千万级甚至亿级表的字段新增操作。
阅读原文:https://mp.weixin.qq.com/s/FtC8GjBhM7yP4_V8u0heZA
该文章在 2025/9/2 13:04:50 编辑过






 400 186 1886
400 186 1886